Tag: adr
Facebook’s “Groups for Schools”: A Harmless Example of a Scary Trend
by chris on Apr.13, 2012, under general
Today brings a guest post from MIT senior (and good friend) Paul Kominers. Full post after the jump.
Facebook, J30Strike, and the Discontents of Algorithmic Dispute Resolution
by chris on Oct.15, 2011, under general
The advent of the Internet brought with it the promise of digitally-mediated dispute resolution. However, the Internet has done more than simply move what might traditionally be called alternative dispute resolution into an online space. It also revealed a void which an entire new class of disputes, and dispute resolution strategies, came to fill. These disputes were the sorts of disputes that were too small or numerous for the old systems to handle. And so they had burbled about quietly in the darkness – bargaining deep in the shadow of the law and of traditional ADR – until the emerging net of digitally designed dispute resolution captured, organized, and systematized the process of resolving them.
In most respects these systems have provided tremendous utility. I can buy things confidently on eBay with my Paypal account, knowing that should I be stiffed some software will sort it out (partially thanks to NCTDR, which helped eBay develop their system). Such systems can scale in a way that individually-mediated dispute resolution never could (with all due apologies to the job prospects of budding online ombudsmen) and, because of this, actually help more people than could be possible without them.
We might usefully distinguish between two types of digital dispute resolution:
- Online Dispute Resolution: individually-mediated dispute resolution which occurs in a digital environment
- Algorithmic Dispute Resolution: dispute resolution consisting primarily of processes which determine decisions based on their preexisting rules, structures, and design
As I said before, algorithmic dispute resolution has provided tremendous utility to countless people. But I fear that, for other digital disputes of a different character, such processes pose tremendous dangers. Specifically, I am concerned about the implications of algorithmic dispute resolution for disputes arising over the content of speech which occurs in online spaces.
In the 1990s, when the Communications Decency Act was litigated, the Court described the Internet as a civic common for the modern age (“any person with a phone line can become a town crier with a voice that resonates farther than it could from any soapbox”). Today’s Internet, however, looks and acts much more like a mall, where individuals wander blithely between retail outlets that cater to their wants and needs. Even the social network spaces of today function more like, say, a bar or restaurant, a place to sit and socialize, than they do a common. And while analysts may disagree about the degree to which the Arab Spring was faciliated by online communication; it is uncontested that whatever communication occurred did so primarily within privately enclosed networked publics like Twitter and Facebook as opposed to simply across public utilities and protocols like SMTP and BBSes.
The problem, from a civic perspective, of speech occurring in privately administered spaces is that it is not beholden to public priorities. Unlike the town common, where protestors assemble consecrated by the Constitution, private spaces operate under their own private conduct codes and security services. In this enclosed, electronic world, disputes about speech need not conform to Constitutional principles, but rather to the convenience of the corporate entity which administrates the space. And such convenience, more often than not, does not concord with the interests of civic society.
Earlier this year, in June 2011, British protestors launched the J30Strike movement in protest of austerity measures imposed by the government. The protestors intended to organized a general strike on June 30th (hence, J30Strike). They purchased the domain name J30Strike.org, began blogging, and tries to spread the word online. Inspired, perhaps, by their Arab Spring counterparts, British protestors turned to Facebook, and encouraged members to post the link to their profiles.
What happened next is not entirely clear. What is clear that on and around June 20th, 2011, Facebook began blocking links to J30Strike. Anyone who attempted to post a link to J30Strike received an error message saying that the link “contained blocked content that has previously been flagged for being abusive or spammy.” Facebook also blocked all redirects or short links to J30Strike, and blocked links to sites which linked to J30Strike as well. For a period of time, as far as Facebook and its users were concerned, J30Strike didn’t exist.
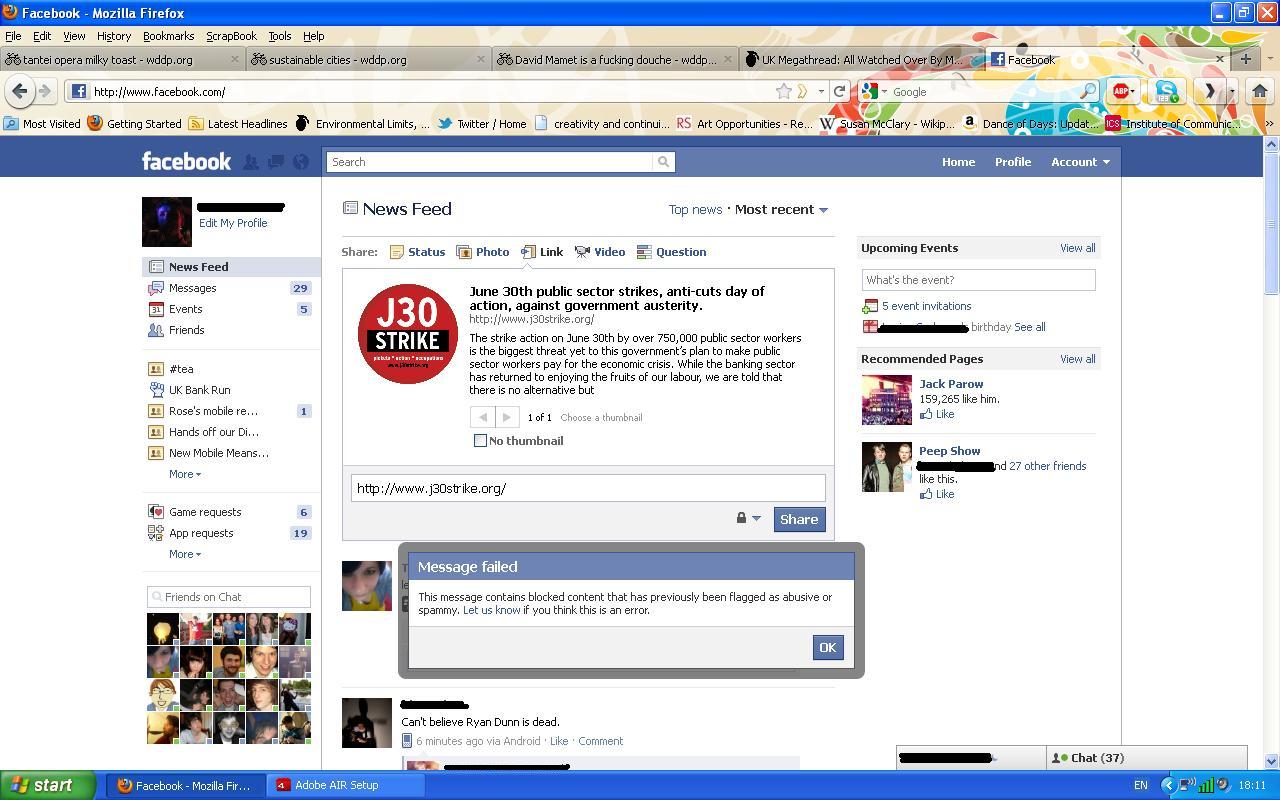{kind=link}
{kind=link}
Despite countless people formally protesting the blocking through Facebook’s official channels, it wasn’t until a muckraking journalist Nick Baumann from Mother Jones contacted Facebook that the problem was fasttracked and block removed. Facebook told Baumann that the block had been “in error” and that they “apologized for [the] inconvenience.”
Some of the initial commentary around the blocking of J30Strike was conspiratorial. The MJ article noted a cozy relationship between Mark Zuckerberg and David Cameron, and others worried about the relationship between Facebook and one of its biggest investors, the arch-conservative Peter Thiel.
Since Facebook’s blocking process is only slightly more opaque than obsidian, we are left to speculate as to how and why the site was blocked. However, I don’t think one needs to reach such sinister conclusions to be troubled by it.
What I think probably happened is something like this: members of J30Strike posted the original link. Some combination of factors – a high rate of posting by J30Strike adherents, a high rate of flagging by J30Strike opponents, and so forth – caused the link to cross a certain threshold and be automatically removed from Facebook. And it took the hounding efforts of a journalist from a provocative publication to get it reinstated. No tinfoil hats required.
But even this mundane explanation deeply troubles me. Because it doesn’t matter, from a civic perspective, is not who blocked the link and why. What matters is that it was blocked at all.
What we see here is an example of algorithmic censorship. There was a process in place at Facebook to resolve disputes over “spammy” or “abusive” links. That process was probably put into place to help prevent the spread of viruses and malicious websites. And it probably worked pretty well for that.
But the design of the process also blocked the spread of a legitimate website advocating for political change. Whether or not the block was due a shadowy ideological opponent of J30Strike or to the automated design of the spam-protection algorithm is inconsequential. Either way, the effect is the same: for a time, it killed the spread of the J30Strike message, automatically trapping free expression in an infinite loop of suppression.
What we have here is fundamentally a problem of dispute resolution in the realm of speech. In public spaces, we have a robust system of dispute resolution for cases involving political speech, which involves the courts, the ACLU, and lots of cultural capital.
Within Facebook? Not so much. On their servers, the dispute was not a matter of weighty Constitutional concerns, but reduced instead to the following question: “based on the behavior of users – flagging and/or posting the J30Strike site – should this speech, in link form, be allowed to spread throughout the Facebook ecosystem?” An algorithm, rather than an individual, mediated the dispute; based on its design, it blocked the link. And while we might accept an blocking error which blocks a link to, say, a nonmalicious online shoe store, I think we must consider blocks of nonmalicious political speech unacceptable from a civic perspective. We have zealously guarded political speech as the most highly protected class of expression, and treated instances of it differently than “other” speech in recognizance of its civic indispensability. But an algorithm is incapable of doing so.
This is censorship. It may be accidental, unintentional, and automated. We may be unable to find an individual on whom to place the moral blame for a particular outcome of a designed process. But none of that changes the fact that it is censorship, and its effects just as poisonous to civic discourse, no matter what the agency – individual or automaton – animating it.
My fear is that we have entered an inescapable age of algorithmic dispute resolution. That we won’t be able to inhabit (or indeed imagine) digital spaces without algorithms to mediate the conversations occurring within. And that these processes – designed with the best of intentions and capabilities – will inevitably throttle the town crier, like a golem turning dumbly on its master.
This post originally appeared on the site of the National Center for Technology and Dispute Resolution.