Tag: j30strike
The Ark in the Archives: Toward a Theory of Link-Oriented Antiepistemology
by chris on Nov.06, 2012, under general
Imagine an expressive object. A book, a painting, or a website will do. This object, in literary terms, constitutes a text, with a meaning to be interpreted by readers.
Assume that a given audience would like to read this text (that is, the text is not already subject to some form of internalized, repressive foreclosure). However, you, for any number of reasons, wish to intercede and prevent them from reading it. How might you go about doing this?
One way to do it would be to act on object itself: that is, to subject the object to some form of overt cultural regulation. If it is a painting, you might ask a museum to remove it from its walls. If it is a book, you might demand a library remove it from its shelves, or even organize a burning in the town common. If it is an embarrassing or dangerous government secret, you might classify it and keep it under lock and key, available to only those with the proper clearance.
Professor Peter Galison’s article Removing Knowledge discusses the processes and practices of classifying documents. Galison notes that, if one counts pages, the volume of classified material produced each year far outstrips that entered into the Library of Congress. “Our commonsense picture may well be far too sanguine, even inverted,” Galison writes. “The closed world is not a small strongbox in the corner of our collective house of codified and stored knowledge. It is we in the open world—we who study the world lodged in our libraries, from aardvarks to zymurgy, we who are living in a modest information booth facing outwards, our unseeing backs to a vast and classified empire we barely know.”
Establishing this empire, Galison notes, was no trivial task. There was a method to the muzzling. He traces the long and (perhaps ironically) well-documented history to how classification schemes developed: carefully, thoughtfully, with almost academic rigor. Indeed, the intellectual character of classifying information inspires Galison to compare it directly to the philosophy of information. He writes: “Epistemology asks how knowledge can be uncovered and secured. Antiepistemology asks how knowledge can be covered and obscured. Classification, the antiepistemology par excellence, is the art of nontransmission.”
Classification, as antiepistemology, orbits the objects it classifies. We might, at the risk of compounding jargon, even call it an object-oriented antiepistemology. Depending on its status, the thing to be classified – a covert intervention, a nuclear equation – then becomes regulated in ways prescribed by the rubric which classified it.
This is a powerful antiepistemology. But are there other antiepistemologies? Other modes of intervention which might make texts unavailable to readers?
Suppose, instead of removing or destroying the object, one attempted to erase avenues through which the object is available. This view imagines object sitting, not “out there” in the open world, but rather entangled at the intersection of the routes which lead to and away from it. As LaTour said at a GSD lecture in 2009, “…we always tend to exaggerate the extent to which we access this global sphere…There is no access to the global for the simple reason that you always move from one place to the next through narrow corridors without ever being outside.”
How might this work in practice?
Indiana Jones: Raiders of the Lost Ark concludes with the Ark, enclosed in an anonymous box, being wheeled into an enormous archive. The scene implies the box will here be kept, secret among secrets, until “top men” begin their work.
Suppose you’re Indiana Jones. Having witnessed the awesome and terrible power of the Ark, you want to prevent even these “top men” from accessing it. What do you do?
You could focus on the object and try to remove the Ark from the archives. But stealing the Ark seems like a difficult task, even someone as resourceful as Indy. His efforts might evenbackfire by alerting the government to his efforts, which, its attention raised, would double-down on securing and preserving the Ark. And even if he did manage to sneak it out, what would he do with such the very dangerous object suddenly in his sole possession?
But Indy could also do something else. If he is worried about “top men” finding the Ark, rather than removing it he could render it unfindable. He might, for example, find the index of boxes and simply edit or erase the Ark’s entry. In an archive of sufficient size and complexity, it seems likely no “top man” would know where or how to find it. In fact, most people wouldn’t even know it had gone missing. The Ark could be hidden in plain sight, simultaneously accessible and unavailable. The routes of passage leading to and from it would not be closed or blocked. Instead, by virtue of the altered indices, they would simply be made to seem boring or unusable to potential travellers.
If classification is object-oriented antiepistemology, then we might call this link-oriented antiepistemology. Link-oriented antiepistemology functions, not by removing or conspicuously blocking access to objects, but by erasing or making uninteresting the avenues which lead to them.
Object-oriented antiepistemology is common to the Internet. Every time a country or company erects a filter or a block, or every time Anonymous fires the LOIC at an underequipped server, they practice censorship by attacking objects. I would argue, however, that instances of link-oriented antiepistemology are emerging on the Internet.
In summer 2011, as the heat and the hardship both beat down on Britain, anti-austerity activists proposed a general strike. They began organizing and promoting the event, relying, as so many groups have, upon digital platforms to spread the word. They set up a website at J30Strike.org and shared links to it on Facebook, trusting that referral traffic would amplify their message across their networks.
Their trust was betrayed when, ten days before the strike, Facebook began blocking all links to J30Strike.org. Attempts were met with a message which said the post “contains blocked content that has previously been flagged as abusive or spammy.†(Emphasis mine). Then, with relentless, recursive efficiency, Facebook blocked links to sites which linked to J30Strike, including blog posts informing other activists of the original embargo. The site was suppressed, and then its suppression was suppressed further.
J30Strike.org underwent a Rumsfeldian transformation, becoming an unknown unknown within the world of Facebook. It’s tempting to say that J30Strike disappeared down the memory hole, but in fact almost precisely the opposite occurred. The original object – the website – remained intact. What vanished were important avenues through which it could be found.
The story of J30Strike could be an instance of link-oriented antiepistemology. Social media appear to connect users directly to their friends such that they may share stories. But in fact, these apparently direct connections have a highly contingent character. What one can see, and what others are allowed to see, depend upon a complex and invisible confluence of forces, many of which were beyond any individual’s control.
If classification regimes are instances of object-oriented antiepistemology, than we might think of J30Strike – or the Digg Patriots – as instances of link-oriented antiepistemology. The objects (J30Strike.org; a DailyKos post about climate change) remain “visitable”. But few visit, because certain tactics have made the indices or routes which lead to them disappear or become utterly uninteresting.
One of the most fascinating and dangerous characteristics of this form of suppression is its silence. This mode of suppression suppresses its own operation. When an object is (often loudly) removed, the knowledge that something is forbidden engenders intense, taboo-driven interest in revealing it. But the erasure of avenues operates invisibly. It rarely betrays its own existence. It requires no clearances, vaults, or bonfires. And it is all the more effective and insidious for it.
This entry was originally posted to the blog of the Center for Civic Media.
Facebook, J30Strike, and the Discontents of Algorithmic Dispute Resolution
by chris on Oct.15, 2011, under general
The advent of the Internet brought with it the promise of digitally-mediated dispute resolution. However, the Internet has done more than simply move what might traditionally be called alternative dispute resolution into an online space. It also revealed a void which an entire new class of disputes, and dispute resolution strategies, came to fill. These disputes were the sorts of disputes that were too small or numerous for the old systems to handle. And so they had burbled about quietly in the darkness – bargaining deep in the shadow of the law and of traditional ADR – until the emerging net of digitally designed dispute resolution captured, organized, and systematized the process of resolving them.
In most respects these systems have provided tremendous utility. I can buy things confidently on eBay with my Paypal account, knowing that should I be stiffed some software will sort it out (partially thanks to NCTDR, which helped eBay develop their system). Such systems can scale in a way that individually-mediated dispute resolution never could (with all due apologies to the job prospects of budding online ombudsmen) and, because of this, actually help more people than could be possible without them.
We might usefully distinguish between two types of digital dispute resolution:
- Online Dispute Resolution: individually-mediated dispute resolution which occurs in a digital environment
- Algorithmic Dispute Resolution: dispute resolution consisting primarily of processes which determine decisions based on their preexisting rules, structures, and design
As I said before, algorithmic dispute resolution has provided tremendous utility to countless people. But I fear that, for other digital disputes of a different character, such processes pose tremendous dangers. Specifically, I am concerned about the implications of algorithmic dispute resolution for disputes arising over the content of speech which occurs in online spaces.
In the 1990s, when the Communications Decency Act was litigated, the Court described the Internet as a civic common for the modern age (“any person with a phone line can become a town crier with a voice that resonates farther than it could from any soapbox”). Today’s Internet, however, looks and acts much more like a mall, where individuals wander blithely between retail outlets that cater to their wants and needs. Even the social network spaces of today function more like, say, a bar or restaurant, a place to sit and socialize, than they do a common. And while analysts may disagree about the degree to which the Arab Spring was faciliated by online communication; it is uncontested that whatever communication occurred did so primarily within privately enclosed networked publics like Twitter and Facebook as opposed to simply across public utilities and protocols like SMTP and BBSes.
The problem, from a civic perspective, of speech occurring in privately administered spaces is that it is not beholden to public priorities. Unlike the town common, where protestors assemble consecrated by the Constitution, private spaces operate under their own private conduct codes and security services. In this enclosed, electronic world, disputes about speech need not conform to Constitutional principles, but rather to the convenience of the corporate entity which administrates the space. And such convenience, more often than not, does not concord with the interests of civic society.
Earlier this year, in June 2011, British protestors launched the J30Strike movement in protest of austerity measures imposed by the government. The protestors intended to organized a general strike on June 30th (hence, J30Strike). They purchased the domain name J30Strike.org, began blogging, and tries to spread the word online. Inspired, perhaps, by their Arab Spring counterparts, British protestors turned to Facebook, and encouraged members to post the link to their profiles.
What happened next is not entirely clear. What is clear that on and around June 20th, 2011, Facebook began blocking links to J30Strike. Anyone who attempted to post a link to J30Strike received an error message saying that the link “contained blocked content that has previously been flagged for being abusive or spammy.” Facebook also blocked all redirects or short links to J30Strike, and blocked links to sites which linked to J30Strike as well. For a period of time, as far as Facebook and its users were concerned, J30Strike didn’t exist.
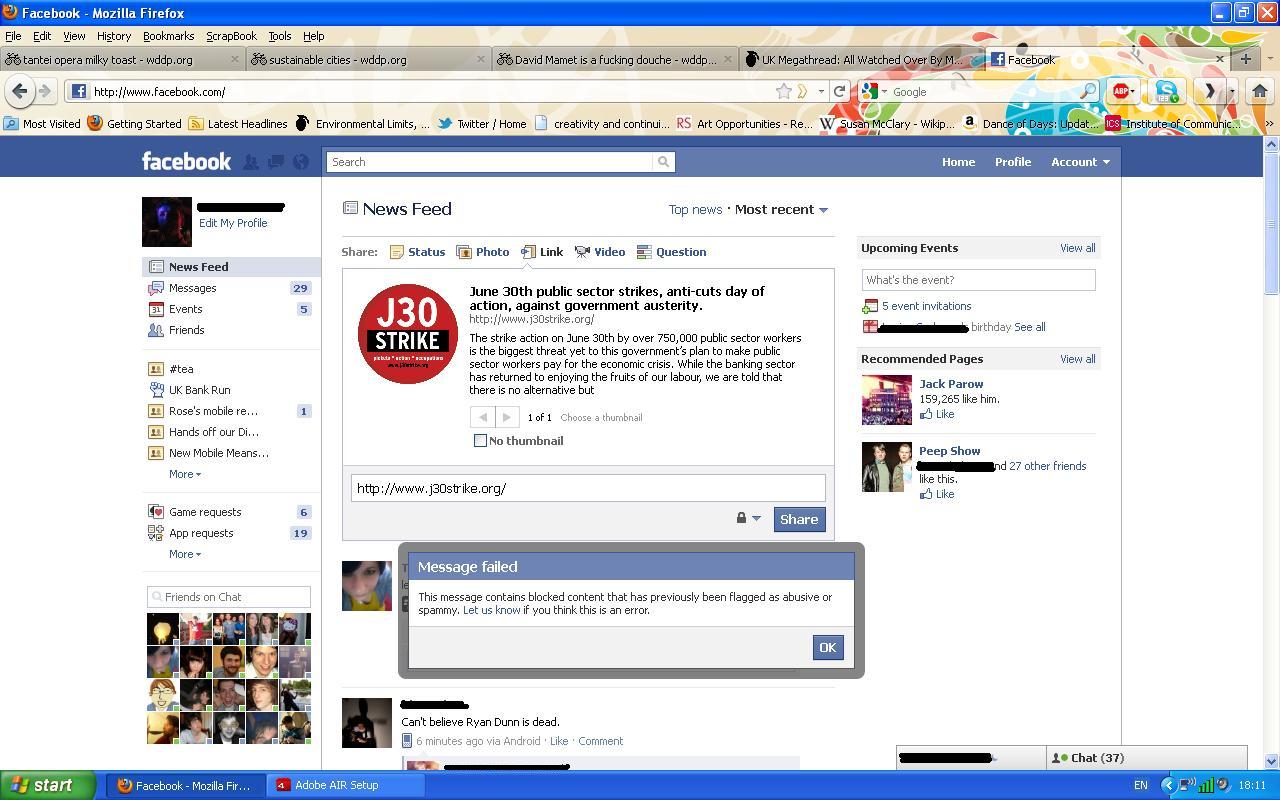{kind=link}
{kind=link}
Despite countless people formally protesting the blocking through Facebook’s official channels, it wasn’t until a muckraking journalist Nick Baumann from Mother Jones contacted Facebook that the problem was fasttracked and block removed. Facebook told Baumann that the block had been “in error” and that they “apologized for [the] inconvenience.”
Some of the initial commentary around the blocking of J30Strike was conspiratorial. The MJ article noted a cozy relationship between Mark Zuckerberg and David Cameron, and others worried about the relationship between Facebook and one of its biggest investors, the arch-conservative Peter Thiel.
Since Facebook’s blocking process is only slightly more opaque than obsidian, we are left to speculate as to how and why the site was blocked. However, I don’t think one needs to reach such sinister conclusions to be troubled by it.
What I think probably happened is something like this: members of J30Strike posted the original link. Some combination of factors – a high rate of posting by J30Strike adherents, a high rate of flagging by J30Strike opponents, and so forth – caused the link to cross a certain threshold and be automatically removed from Facebook. And it took the hounding efforts of a journalist from a provocative publication to get it reinstated. No tinfoil hats required.
But even this mundane explanation deeply troubles me. Because it doesn’t matter, from a civic perspective, is not who blocked the link and why. What matters is that it was blocked at all.
What we see here is an example of algorithmic censorship. There was a process in place at Facebook to resolve disputes over “spammy” or “abusive” links. That process was probably put into place to help prevent the spread of viruses and malicious websites. And it probably worked pretty well for that.
But the design of the process also blocked the spread of a legitimate website advocating for political change. Whether or not the block was due a shadowy ideological opponent of J30Strike or to the automated design of the spam-protection algorithm is inconsequential. Either way, the effect is the same: for a time, it killed the spread of the J30Strike message, automatically trapping free expression in an infinite loop of suppression.
What we have here is fundamentally a problem of dispute resolution in the realm of speech. In public spaces, we have a robust system of dispute resolution for cases involving political speech, which involves the courts, the ACLU, and lots of cultural capital.
Within Facebook? Not so much. On their servers, the dispute was not a matter of weighty Constitutional concerns, but reduced instead to the following question: “based on the behavior of users – flagging and/or posting the J30Strike site – should this speech, in link form, be allowed to spread throughout the Facebook ecosystem?” An algorithm, rather than an individual, mediated the dispute; based on its design, it blocked the link. And while we might accept an blocking error which blocks a link to, say, a nonmalicious online shoe store, I think we must consider blocks of nonmalicious political speech unacceptable from a civic perspective. We have zealously guarded political speech as the most highly protected class of expression, and treated instances of it differently than “other” speech in recognizance of its civic indispensability. But an algorithm is incapable of doing so.
This is censorship. It may be accidental, unintentional, and automated. We may be unable to find an individual on whom to place the moral blame for a particular outcome of a designed process. But none of that changes the fact that it is censorship, and its effects just as poisonous to civic discourse, no matter what the agency – individual or automaton – animating it.
My fear is that we have entered an inescapable age of algorithmic dispute resolution. That we won’t be able to inhabit (or indeed imagine) digital spaces without algorithms to mediate the conversations occurring within. And that these processes – designed with the best of intentions and capabilities – will inevitably throttle the town crier, like a golem turning dumbly on its master.
This post originally appeared on the site of the National Center for Technology and Dispute Resolution.
Facebook vs Ebert
by chris on Jun.21, 2011, under general
On the heels of the J30Strike fiasco, Facebook has turned its auto-censor cannon at…Ebert?
For movie critic Roger Ebert, it took only hours to criticize the late Jackass star Ryan Dunn for drinking and driving. Facebook just as swiftly took the film critic’s page down.
Dunn had died in a car crash that also took his friend’s life. After Ebert’s post about the late Jackass star, Facebook pulled the page and put up a placeholder disclaimer saying that the site doesn’t allow pages with hateful, threatening or obscene content.
Facebook spokesperson Andrew Noyes told us via email, “The page was was removed in error. We apologize for the inconvenience.â€
My guess is something similar happened to J30Strike here. Lots of people flagged the post as abusive and the page was taken down.
I don’t support speaking ill of the dead. But I don’t think you need to in order to think this is also a dumb and bad decision. And Noyes’ response is exactly the same as yesterday, leading me to believe this happens fairly often.
The problem, of course, is that Ebert has a lot of clout, and J30Strike censorship ended after an investigative reporter called.
What about the folks who don’t have that much power? Are their rights restored as rapidly? I doubt it. And that still troubles me.